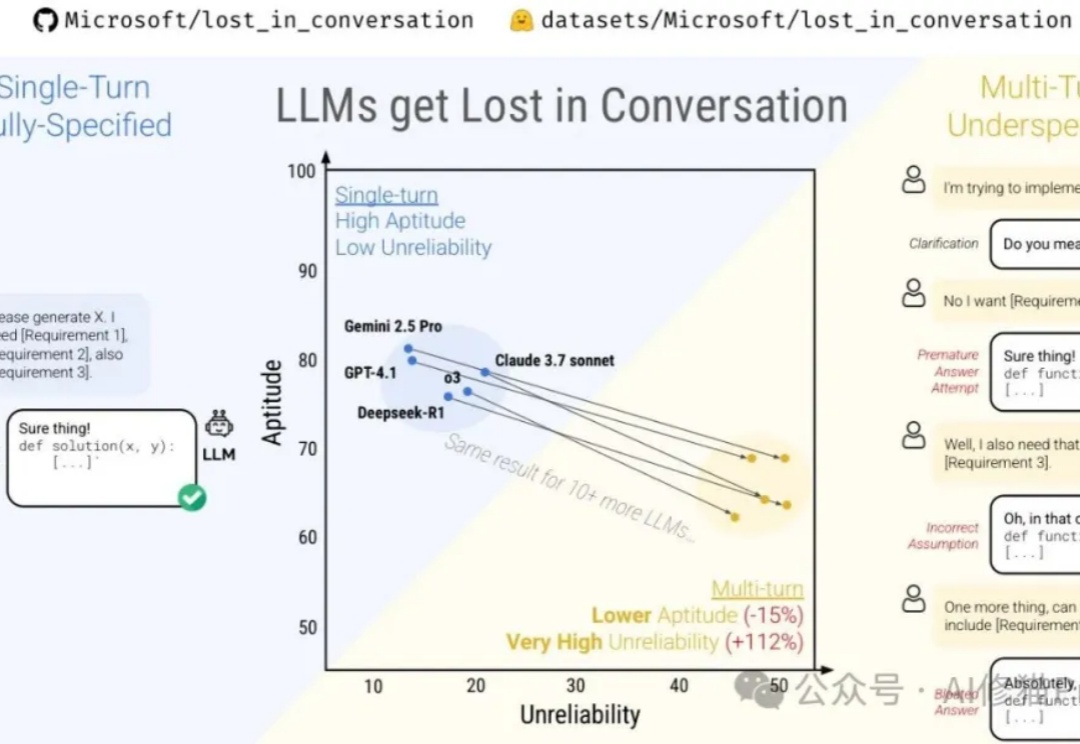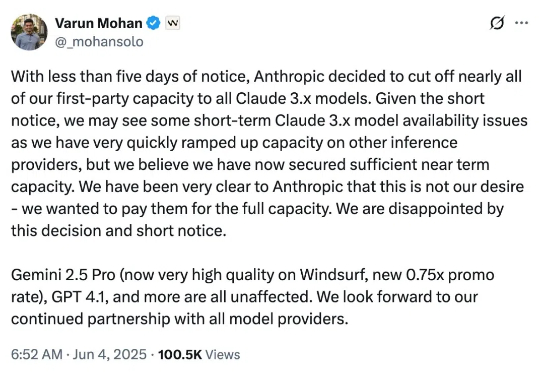
天塌了,Claude 全面断供Windsurf!CEO喊冤控诉也挡不住开发者退订,祸起OpenAI收购?
天塌了,Claude 全面断供Windsurf!CEO喊冤控诉也挡不住开发者退订,祸起OpenAI收购?当地时间 6 月 4 日,Windsurf CEO Varun Mohan 发帖称,在提前不到五天的通知时间里,Anthropic 切断了其几乎所有 Claude 3.x 模型的直接访问权限(first-party capacity),包括 Claude 3.5 Sonnet、3.7 Sonnet 和 3.7 Sonnet Thinking。
来自主题: AI资讯
9005 点击 2025-06-04 16:36